The AMoC project (Adaptive Multiprocessors-on-Chip) is funded by the Deutsche Forschungsgemeintschaft (German Research Foundation) and focusses on the design of adaptive reconfigurable chip multiprocessor systems. Therefore, a design methodology for FPGA-based (Field- Programmable Gate Array) multiprocessorsystems on chip was developed and can be seen in the following figure:
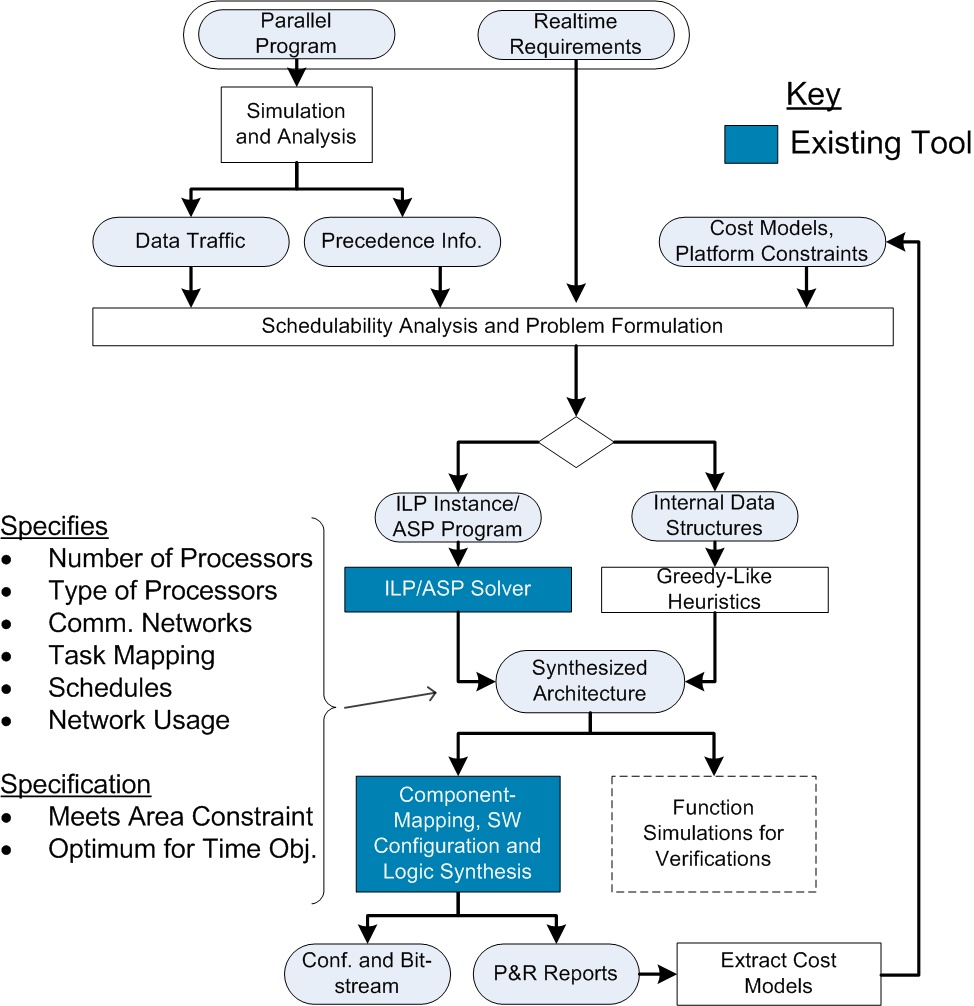
Design Flow
The architectural synthesis flow starts with a MPI parallel program and ends with a bit-stream used for the configuration of an FPGA. In this case, the communication in the parallel program need to be described with MPI (Message Passing Interface). The application is then simulated and analyzed to obtain information about task precedence and inter-task data traffic. This information is used to specify an instance of an Integer Linear Program (ILP) problem [1,2,3]. Additionally, information on processing elements and communication networks, especially their costs and constraints, for a target platform is needed. That is, in the case of Xilinx FPGAs for instance the actual size of the FPGA, costs for the available processing elements, like MicroBlaze soft-core processor or PowerPC hard-core processor or the bandwidth and latency of communication networks. In this approach, the design-space of the ILP problem is not pre-constrained, and the problem dimensions are not ranked. This insures the optimality of found solutions. However, for system requirements, such as real-time requirements, it is sufficient to meet certain timing constraints, so that the interest is not to find the overall fastest solution, but the smallest instead. The solution to the ILP instance is then used to generate an description of the system, which is passed to the tool-chains to generate the configuration bit-stream. Because post-synthesis results could deviate from initial cost models used, new cost models can optionally be extracted after placement and routing to start a new iteration. SoC-MPI [4], a lightweight and flexible communication library, is used for the software-sided communication of the MPI program after the architecture is determined. However, the SoC-MPI library allows hardware-supported MPI functions and currently covers a subset of the MPI-I specification. This methodology is integrated in the PinHaT (Program-independent Hardware Generation Tool) [5,6], which addionally allows other design entries, like the specification and refinement of the architecture by hand. PinHaT currently supports Xilinx FPGAs and to some degree Altera FPGAs. The architecural synthesis flow is currently extended with a semi-automatic parallelization procedure, which allows the user to take a sequential program and parallelize it, as far as the structure of the program allows. The first work in this field is the parallelization of functions and the inserttion of MPI commands [7] to perform communiction. This straight-forward approach will be extended with the parallelization on block-level, especially the parallelization of loops, which in most cases have a high degree of code which can be executed in parallel. On goal of this parallelization procedure is to conserve the original code and not use an intermediate reprersentaion (three adress code). The flow begins then with the parallelization and insertion of MPI commands and ends with the the configuration bit-stream for the FPGA.
Installation
The tool-chain consists of the graphical frontend, the synthesis engine (ILPF), as well as third-party tools for simulations (MPICH2 and MPE-Library), ILP-solver (lp_solve), ASP-Solver (clasp), and lastly, Xilinx EDK and ISE.
PinHat, ILPF, lp_solve and clasp has been packaged in one convenient package for Windows and Linux . While you will not directly interact with lp_solve and clasp, and no knowledge on these tools is required to work with PinHat, we encourage you to visit their web sites to familiarize yourself.
MPI and Xilinx tools currently require separate installations. You can obtain MPICH2 here. The web site includes excellent installation and introductory information. MPE can be downloaded here. While we are still at it, we encourage you to learn how to develop your parallel programs conforming to the MPI-standard. The standard is intuitive and easy to use. If you are not yet familiar with it, think link provide an excellent tutorial.
Xilinx tools can be directly obtained from the vendor, and they require a license. You also need the Java Runtime Environment. In the unlikely event that your machine has none installed, you can obtain a copy from SUN. ## Download
- A User’s Guide to PinHat Synthesis Engine (Vers. 0.1)
Note that this site is work in progress. PinHaT and the SoC-MPI library will be available soon. ## Publications [1] Harold Ishebabi and Christophe Bobda. Automated architecture synthesis for adaptive multiprocessors on chip systems. In Journal of Microprocessors and Microsystems. Elsevier Science, August 2008.
[2] Harold Ishebabi, Philipp Mahr, and Christophe Bobda. Makespan minimization in automatic synthesis of multiprocessor systems from parallel programs. In IEEE International Conference on Field-Programmable Technology, Taipei, Taiwan, December 2008.
[3] Harold Ishebabi, Philipp Mahr, and Christophe Bobda. Automatic synthesis of multiprocessor systems from parallel programs under preemptive scheduling. In International Conference on ReConFigurable Computing and FPGAs, Cancun, Mexico, December 2008.
[4] Philipp Mahr, Christian Lörchner, Harold Ishebabi, and Christophe Bobda. SoC-MPI: A flexible message passing library for multiprocessor systems-on-chips. In RECONFIG’08: Proceedings of the 2008 International Conference on Reconfigurable Computing and FPGAs, pages 187-192, Washington, DC, USA, 2008. IEEE Computer Society.
[5] Thomas Haller, Felix Mühlbauer, Dennis Rech, Simon Jung, and Christophe Bobda. Design of adaptive multiprocessor on chip systems. In SBCCI’07: Proceedings of the 20th annual conference on Integrated circuits and systems design, pages 177-183, New York, NY, USA, 2007. ACM.
[6] Philipp Mahr, Harold Ishebabi, Benjamin Andres, Christian Lörchner, Michael Metzner and Christophe Bobda: Automated Design Approach for on-Chip Multiprocessor Systems, FPGAworld Conference 2008, 11.09.2008, Stockholm, Sweden.
[7] Philipp Mahr, Benjamin Andres, Harold Ishebabi and Christophe Bobda: A Design Methodology for Reconfigurable Heterogeneous Architectures, Many-Core and Reconfigurable Supercomputing Conference 2009 (MRSC’09), Berlin, Germany, March 25-26, 2009.
[8] H. Ishebabi, P. Mahr, C. Bobda, M. Gebser, T. Schaub: Application of ASP for Automatic Synthesis of Flexible Multiprocessor Systems from Parallel Programs, LPNMR 2009.
[9] H. Ishebabi, P. Mahr, and C. Bobda: PinHaT: Platform independet Hardware generation Tool, University Booth of Design, Automation 2009 (DAC’09), San Fransisco, CA, July 25-31, 2009.
[10] H. Ishebabi, C. Bobda: Heuristics for Flexible CMP Synthesis, Transaction on Computers, submitted May 2009.
[11] H. Ishebabi, P. Mahr, C. Bobda, M. Gebser, T. Schaub: Answer Set vs Integer Linear Programming for Automatic Synthesis of Multiprocessor Systems From Real-Time Parallel Programs, Journal of Reconfigurable Computing, submitted March 2009. ## Contact