Introduction
NICHD reports that close to 4,000 infants die annually from sleep-related causes in the US. Sudden Unexpected Infant Death (SUID) is the leading cause of infant mortality in the US among children aged from 1 month to 1 year old. SUID is defined as the sudden and unexpected death of an infant in cases where the cause is not obvious before an investigation. After a full investigation, SUID may be classified as Sudden Infant Death Syndrome (SIDS), suffocation, trauma, metabolic diseases, or unknown. SIDS is defined as sudden, unexpected infant death that cannot be explained, including scene investigation, autopsy, and clinical history review.
Recently, machine learning (ML) has become an ultimate tool for image classification and segmentation and has shown quality results in both engineering, and healthcare applications. It allows computational models composed of several processing layers to learn representations of data with several levels of abstraction. ML uses two types of techniques: supervised learning, which forms a model on known input and output data so that it can predict future outcomes and unsupervised learning that finds hidden models or structures intrinsic in the input data.
Approach
We used images taken by a convenience sample of teen mothers (TMs), who owned a smartphone and had an infant under 4 months old. The images were independently assessed for coder reliability across five domains of infant safe sleep, including sleep location, surface, position, presence of soft items, and hazards near the sleep area. The criteria for safe sleep practices and environment are defined in Figue 1. The criteria provided the final class values in which we classified each pixel in the images. They help to determine if a sleep environment is safe or not. To do so, each criterion is assigned a specific. From a copy of every image, we manually label each pixel according to the color if it belongs to one of the criterions.

Model’s Architecture
The network architecture is illustrated in Figure 2. The convolutional neural network architecture used here is based on the SegNet architecture for semantic segmentation. The internal architecture of the machine learning model is an encoder-decoder network, followed by a pixel-wise classification layer. This network uses a VGG-style encoder-decoder, where the upsampling in the decoder is done using transposed convolutions. The encoder is a collection of convolutional layers designed to extract feature maps for object classification. It contains 6 convolution layers and 3 pooling layers. The decoder has the same number of layers as the encoder and upsamples its input feature maps using the memorized indices from the corresponding encoder feature maps. The last convolution layer of the decoder feeds a soft-max classifier.
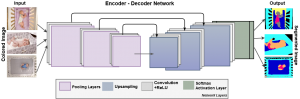
Encoder
Decoder
Training
We build our own dataset called Safe Sleep dataset. This dataset is relatively small, consisting of 486 training and 120 testing color images (day and dusk scenes) at 320 X 240 resolutions. The data set consists of infants in different bed types, positions, clothes and situations. To increase the dataset size, we used some data augmentation techniques such as horizontal flip, vertical flip, 2D random rotation, and brightness alteration. Overall, The model was able to acheive a maximum accuracy of 81%.
Note that this site is work in progress.